
 1552分享
1552分享SdibleDiffusion插件是什么
比如说Controlnet这个插件,可以做出我们想让Ai绘出我们想要的各种动作、大劈叉姿势等,那么我们就需要去安装这些插件才能达成我们的效果。插件怎么来的呢,都是一些野区大佬开发的,如果没有Ta们开发的这些插件,那么SdibleDiffusion就太无聊了,所以就很感谢这些人开发插件供我们免费使用,让我们有很多玩法,因此我们更要学会怎么去用安装和它们。
安装插件
说明
我们以controlney插件为例进行演示,如果你学会这个安装流程,以后安装其他的插件也会知其然更知其所以然,这个也是我推荐大家不要用懒人安装包,用那种噩梦级别的方式安装,遇到问题去对应解决,那么你就会得到更多的经验,遇到疑难杂症就知道如何去解决。
接下来的演示我会以我的汉化版本进行演示,如果你想双语汉化请点击这里的教程查看:StableDiffusion汉化教程
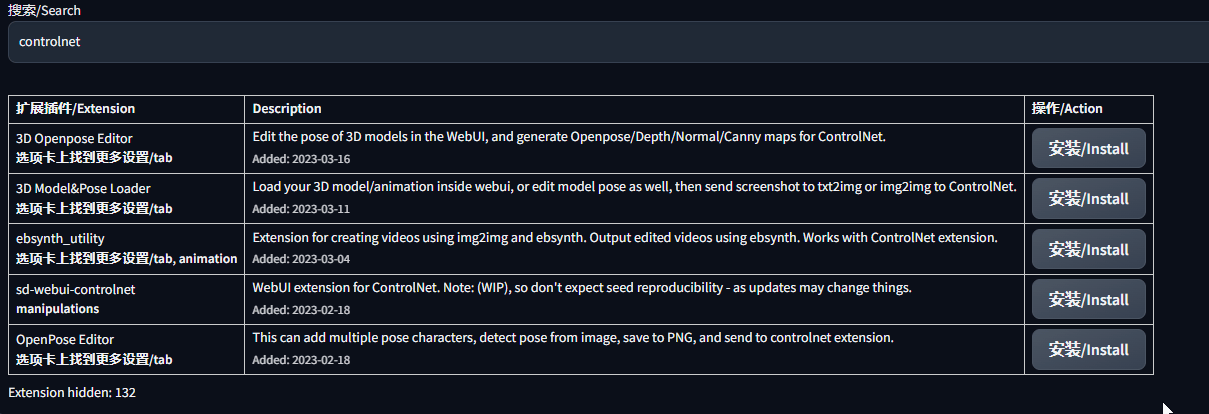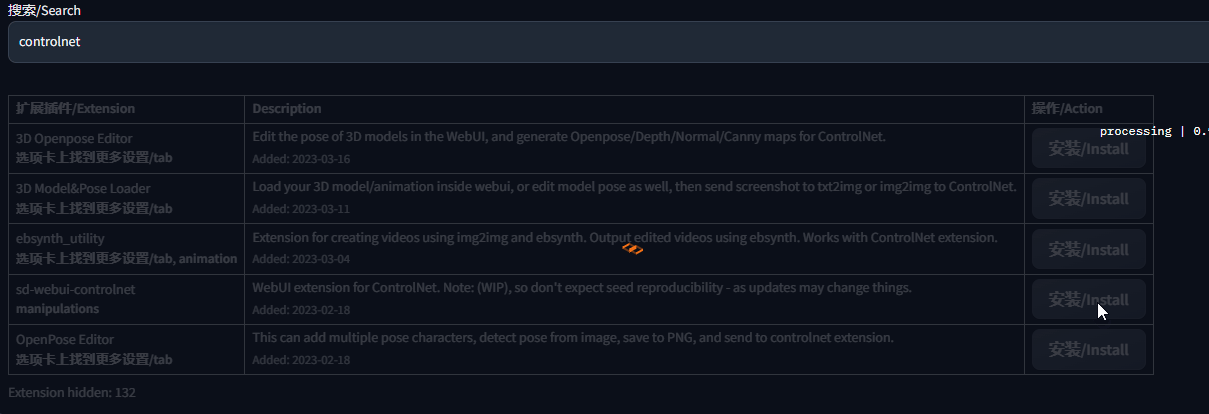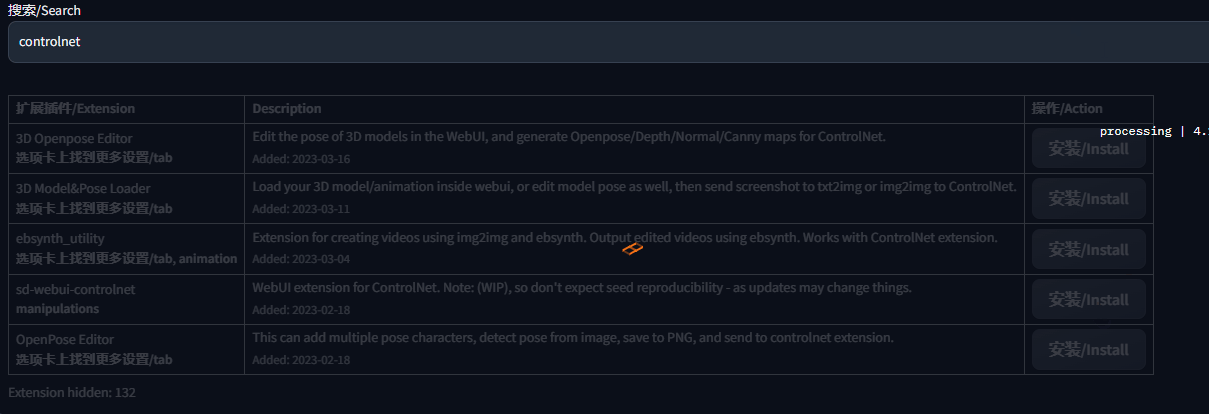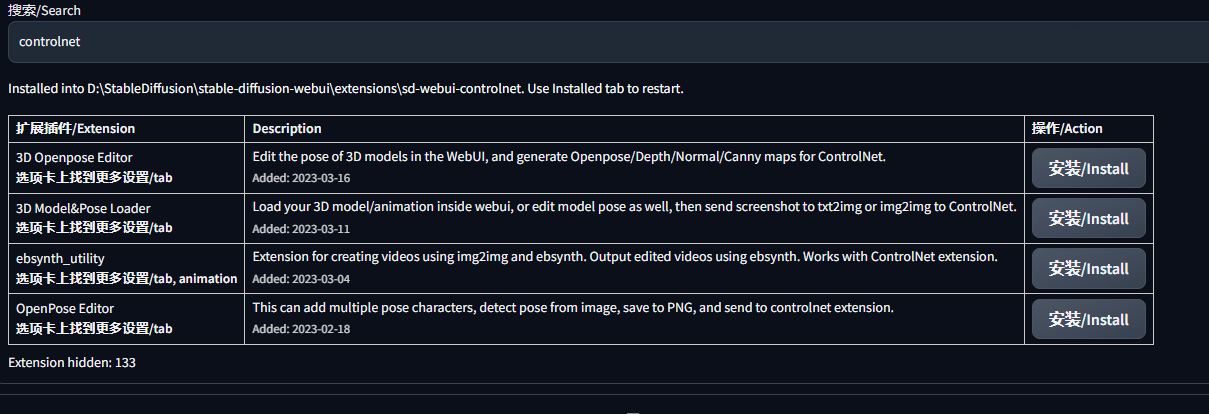
点击右侧扩展插件/扩展如下图所示
点击可用再点击加载自
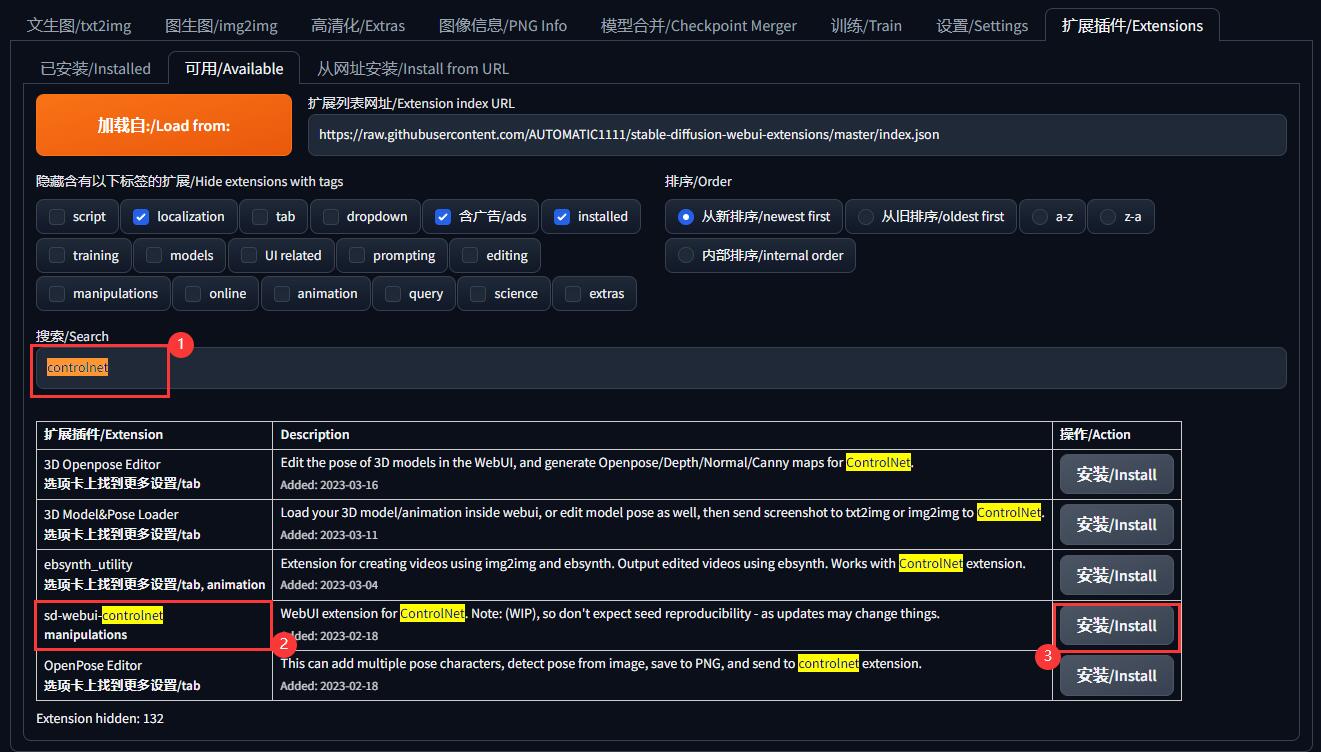
 然后就会加载出特别多的插件,在搜索框输入controlnet它会自动帮我们找到结果,然后选择sd-webui-controlnetmanipulations然后点击安装
然后就会加载出特别多的插件,在搜索框输入controlnet它会自动帮我们找到结果,然后选择sd-webui-controlnetmanipulations然后点击安装/lnstall还有一种快速搜索的方法是按Ctrl+f,用浏览器快速定位关键字,然后去对应下载。
安装根据每个人的网络不同,一般几十秒就安装成功。安装成功后列表的controlnet插件将不显示。
安装成功后,我们可以看一下我们的插件目录是否有controlnet文件了路径是: 根目录的 extensions 文件下可以看到,如下图所示代表我们已经安装成功,也知道原来插件是在这里的。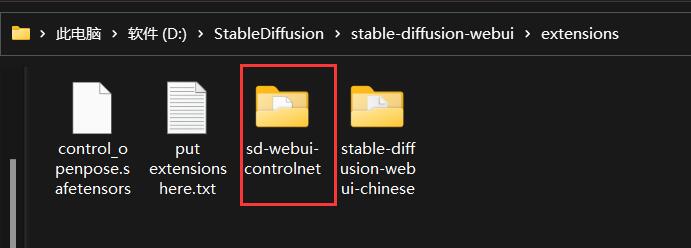
controlnet模型安装
好奇怪,插件都安装了为什么还要安装插件模型,插件还有模型。就像StableDiffusion 没有模型画的图很难看一样,插件也不能缺少灵魂。
controlnet插件模型的路径为:\extensions\sd-webui-controlnet\models
对,和StableDiffusion的模型目录名称一样,都是models

请复制如下网址到浏览器下载controlnet的底模型
https://huggingface.co/Hetaneko/Controlnet-models/tree/main/controlnet_safetensors
如下图为例,模型大小1.45GB左右,我们下载名称为 control_openpose.safetensors 这个模型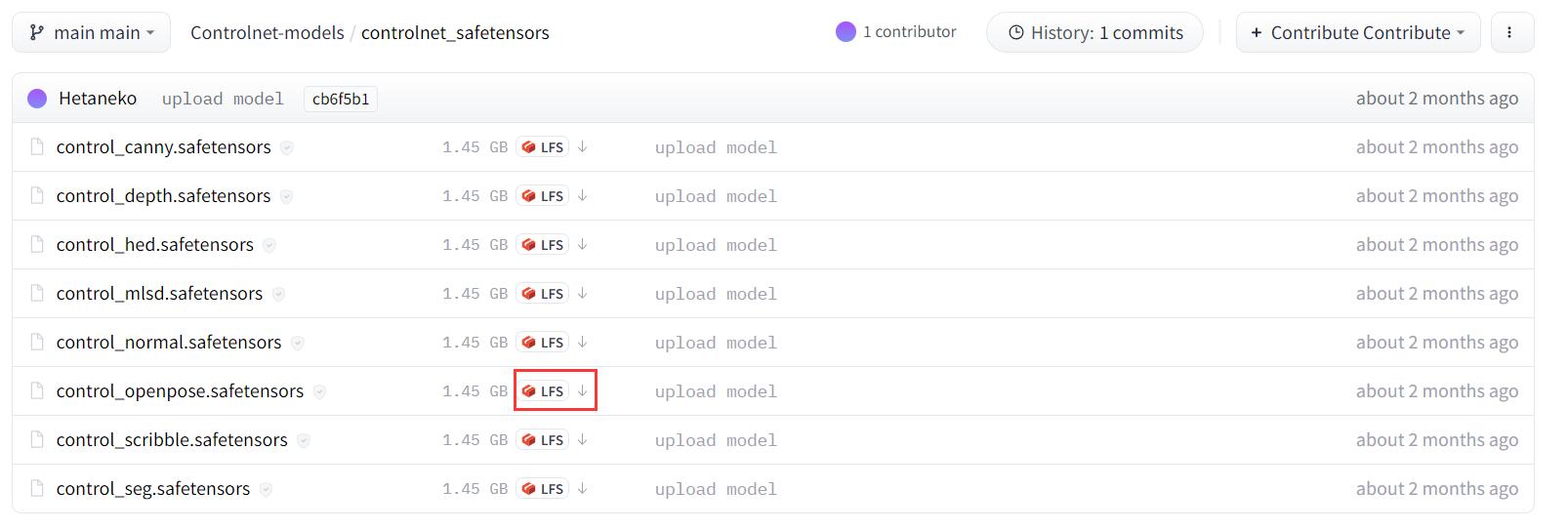
下载完成后,我们把我们下载的模型文件复制到 \extensions\sd-webui-controlnet\models 就可以了。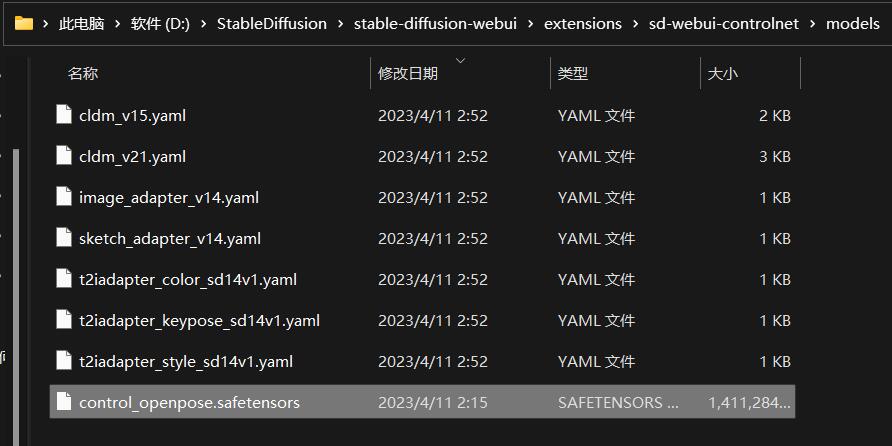
Controlnet插件功能解释
到这里大家已经完成了插件的安装以及模型的下载流程了,我们点击打开 Controlnet
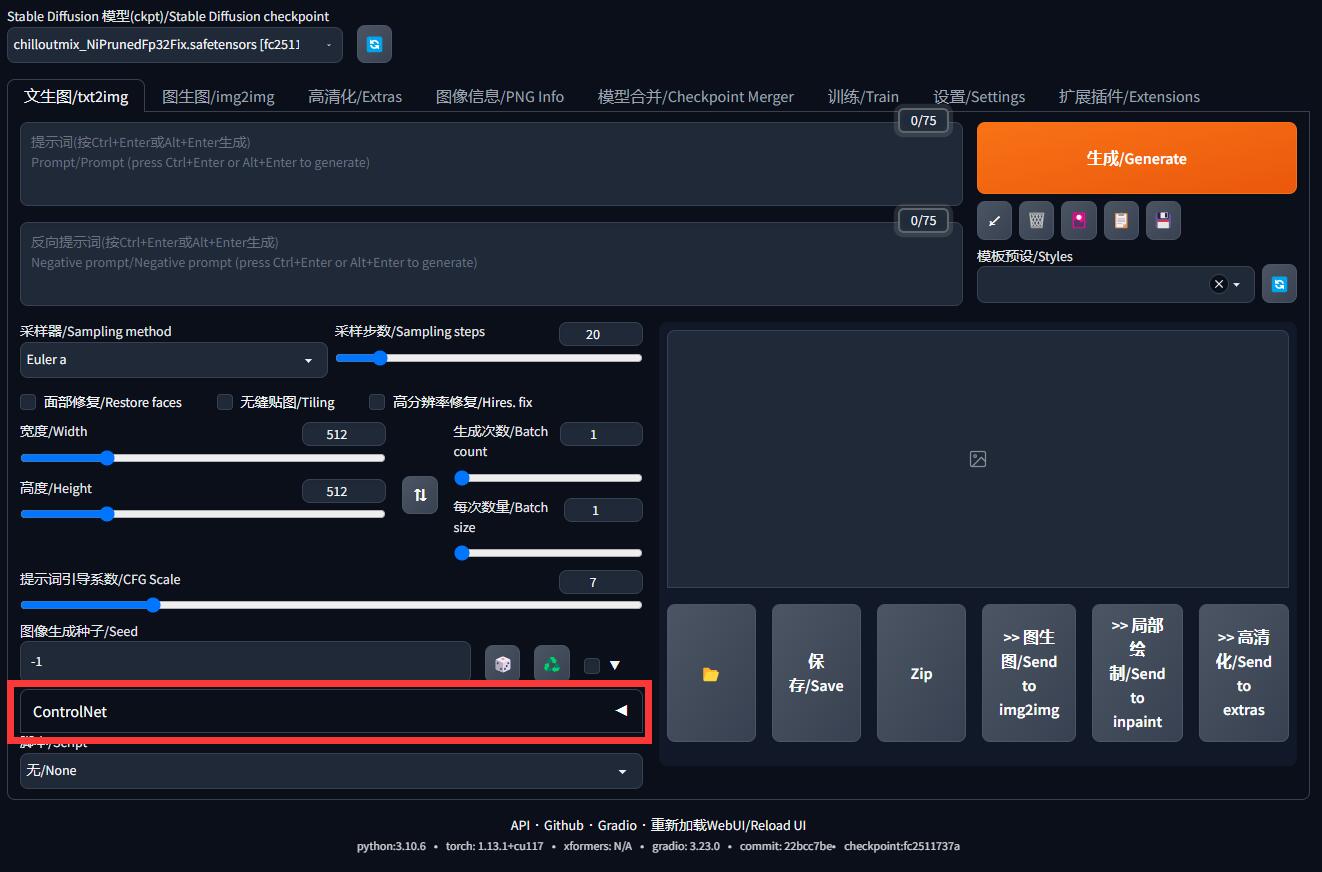
它的插件内容是很长的,我的屏幕都要装不下了。展开后如下图所示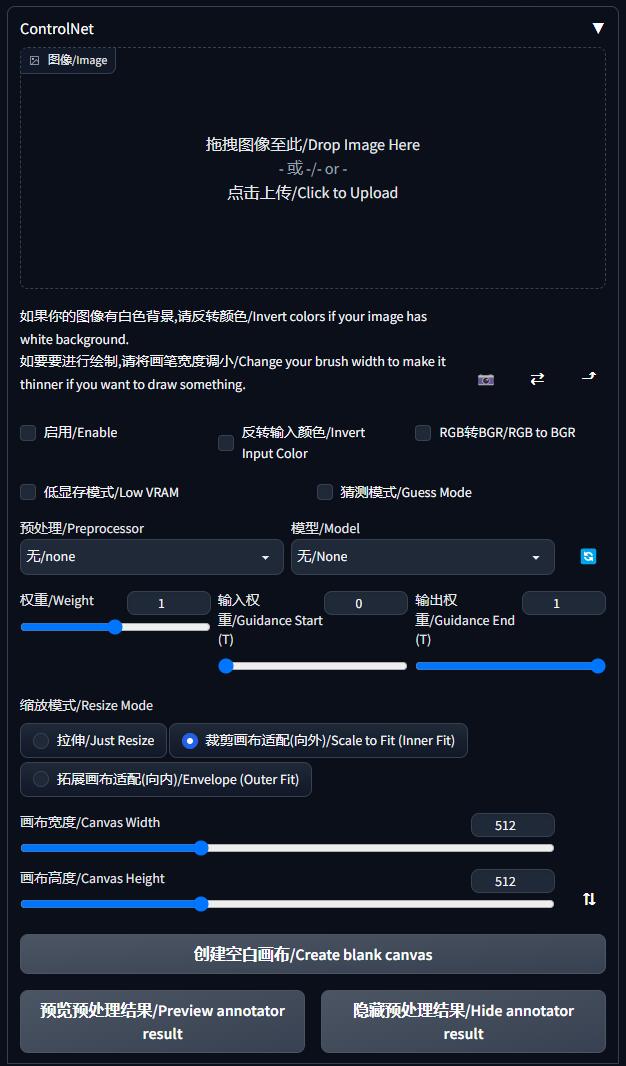
功能按钮用处解释
图像/lmage:这里可以手动往里拖进我们想要的动作图片,或者点击以下导入一张图片。绘画时也会按照你设定的信息画出相同的动作。
红色的字代表:重要的
启动/Enable:只有打勾后这个功能才会生效。
反转输入颜色/Invert Input Color:将导入的图片进行反转
RGB转BGR/RGB to BGR:将通道颜色进行反转
低显存模式/Low VRAM:显卡不够力,就可以勾选这个
猜测模式/Guess Mode:有点类似图生图的意思,按照你导入的图进行生成图片

预处理器:选择姿势手部检测/openpose_hand 其他选项,我在后面解释它的含义。
模型: 选择我们刚刚下载的模型 control_openpose [6b6b0674] 如果没有显示就点击🔄
注意:预处理器用的是 openpose 那么模型也要对用 使用 openpose 模型也是要对应使用的。

权重/Weight:这个值设置的越高,它越倾向于你导入图片的姿势
输入权重/Guidance Start (T):这是一个步数引导,你想要在什么时候开始介入引导。比如说你设值为1,Contornet在生成图片的最后一步开始介入引导;如果你是0,那么它一开始就介入引导了。如果你设置0.28,那么就在你第28%的步数时开始引导。
输出权重/Guidance End (T):它和上面的同理,在多少步数的时候退出介入引导,我喜欢用百分比说步数。比如你设置了20步(采样步数/Sampling steps),你写了0.5,那么生成图片的时候会在第十步的时候退出姿势的引导。默认为1,那么就是不退出。

Annotator Resolution:注射器分辨率,这里的值越高,那么就在预处理结果的精细度也会越高,但也越吃你的显卡性能
画布宽度/Canvas Width和画布高度/Canvas Height:是你以什么比例去读取你导入的图片,比如你设置的图片人物范围是512*768,在生成尺寸设置的是512*512,那么它的原理就像自动裁剪成512*512,裁掉的位置它识别不到,就会发散性的绘制姿势了。
在这里如果你设置了512*768,那么在这里也要对应设置相同参数,否则就会出现照片被裁剪的样子

就像这样,头部和臀部没有漏出来,被裁剪了一样。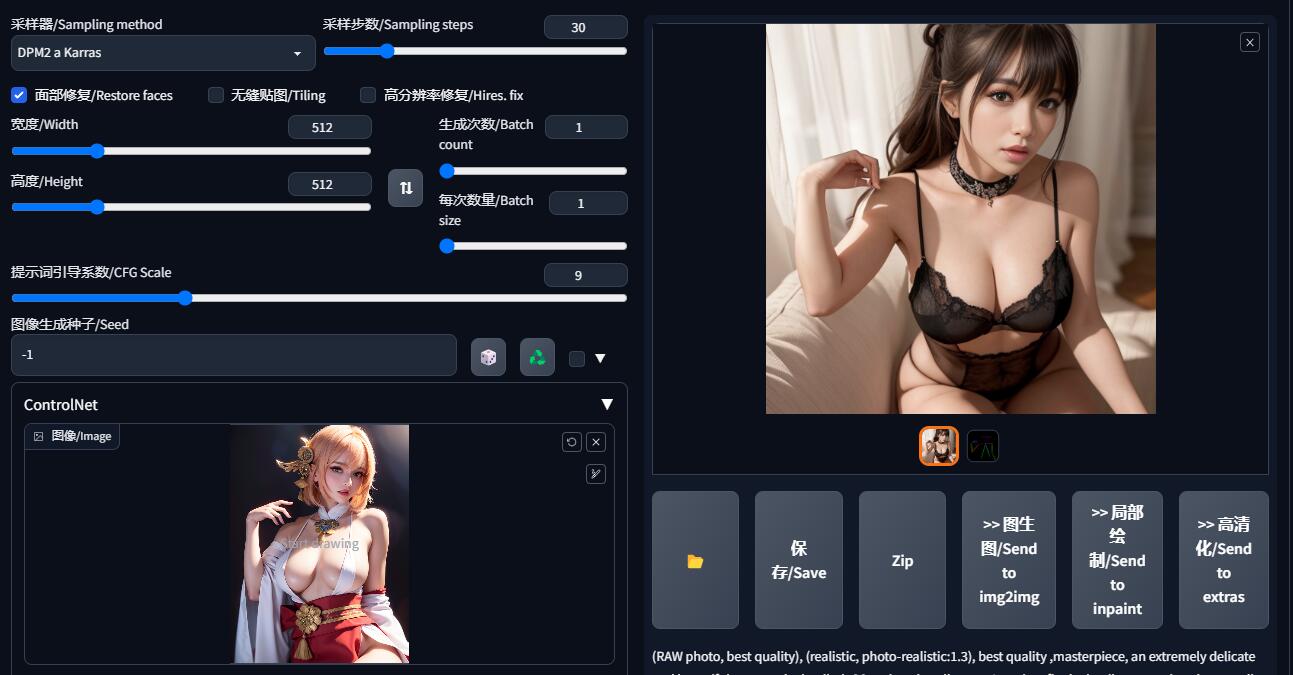
改成对应的后,就是这个效果了
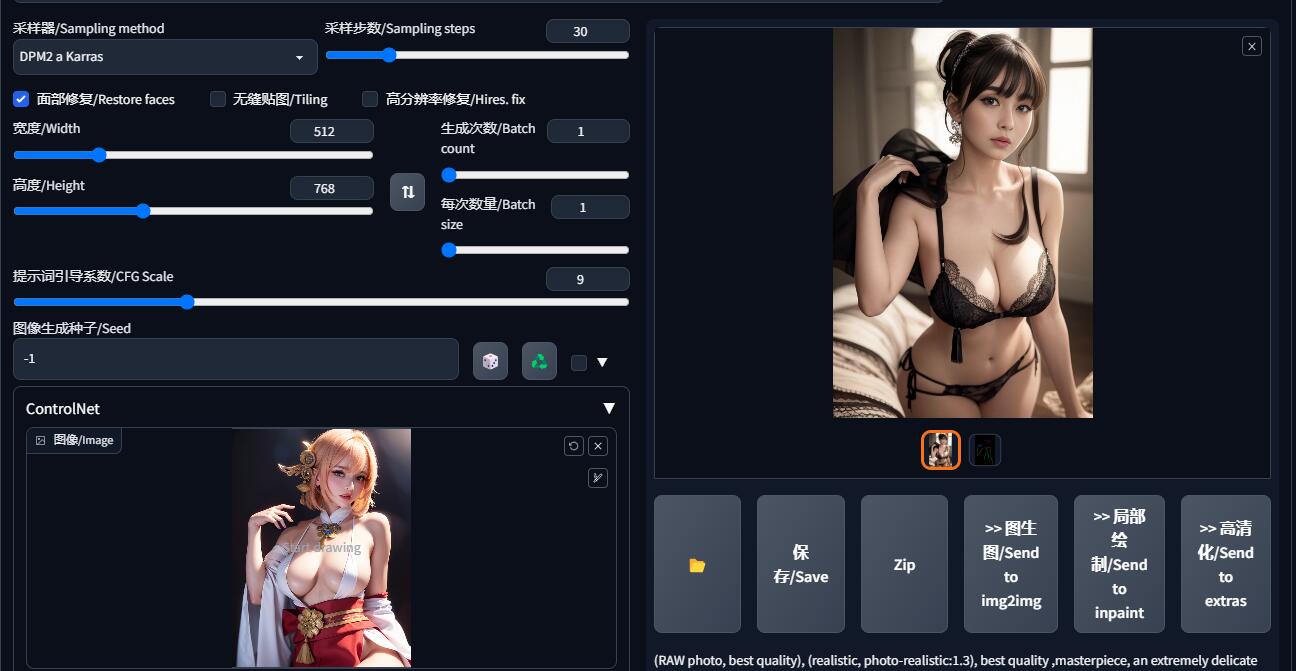
预处理器
在这里,我再解释一下预处理的其他功能有什么用处。
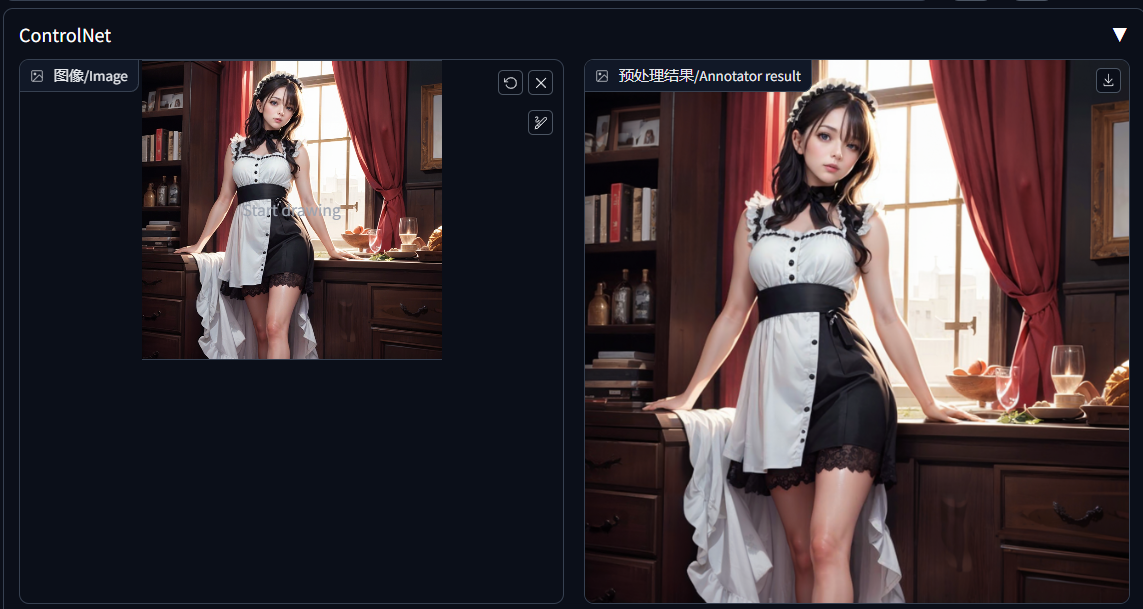
无/none:如果选择无会有很多噪音在里面,根本无法完成我们想要的需求。预处理的面板如下所示
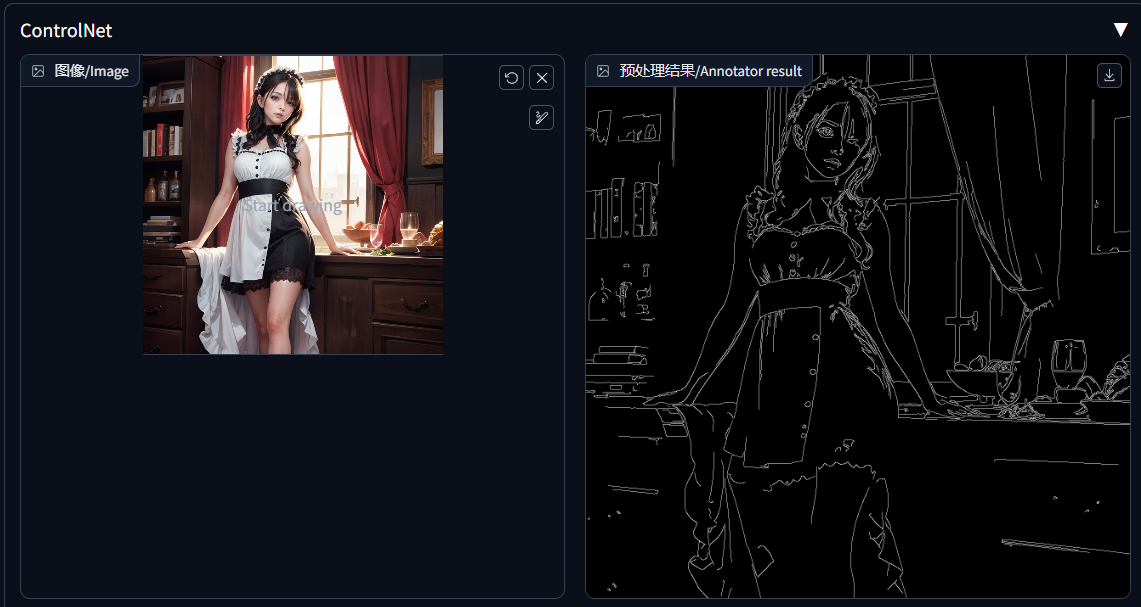
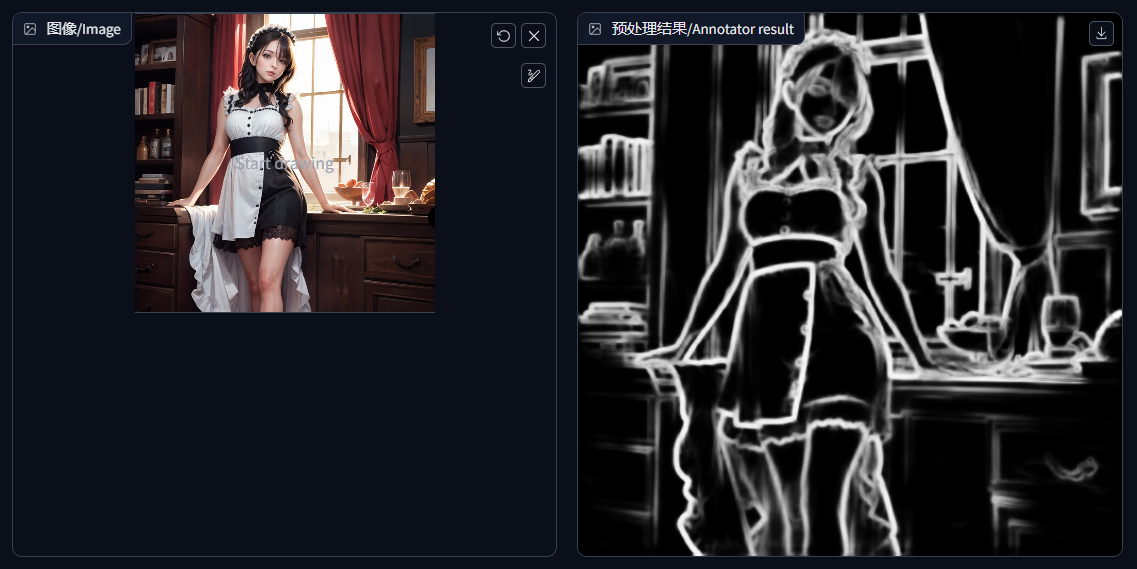
线稿检测/canny:它会把人物,以及周边的景物轮廓描绘出来。当注释器分辨率(Annotator resolution)越高时,它的线条越细。
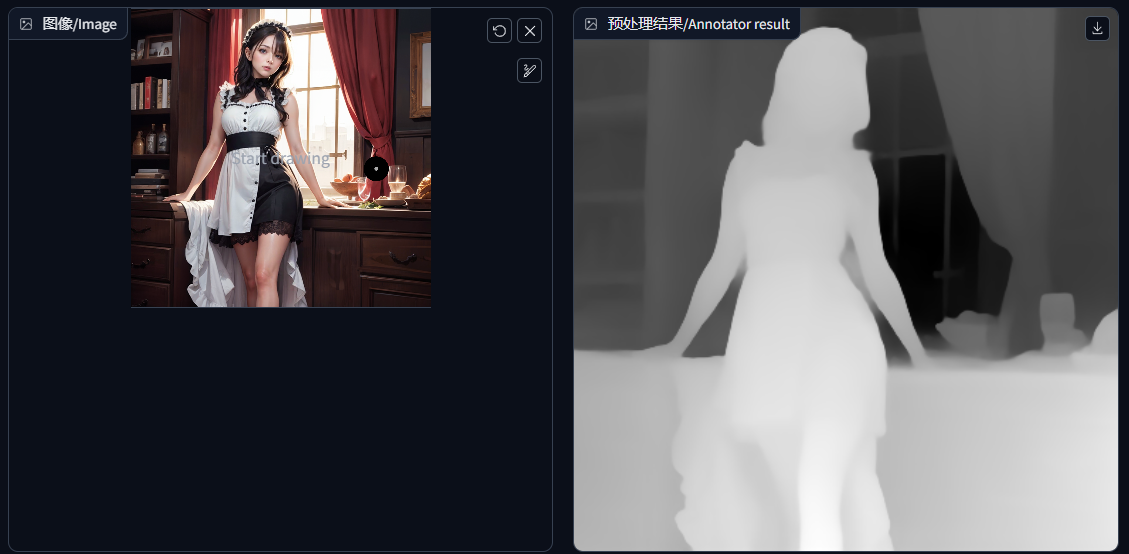
深度检测/depth:它是一个深度图算法,它会捕捉你图片元素前后位置的层次关系,也就是空间关系。白色的是前,黑色是后。
模糊检测/hed:它类似边缘算法,它更像线稿检测/canny算法,有些像手绘画的模糊效果。它这个算法在周围细节它是有得到补充的,对比线稿有更多的细节。
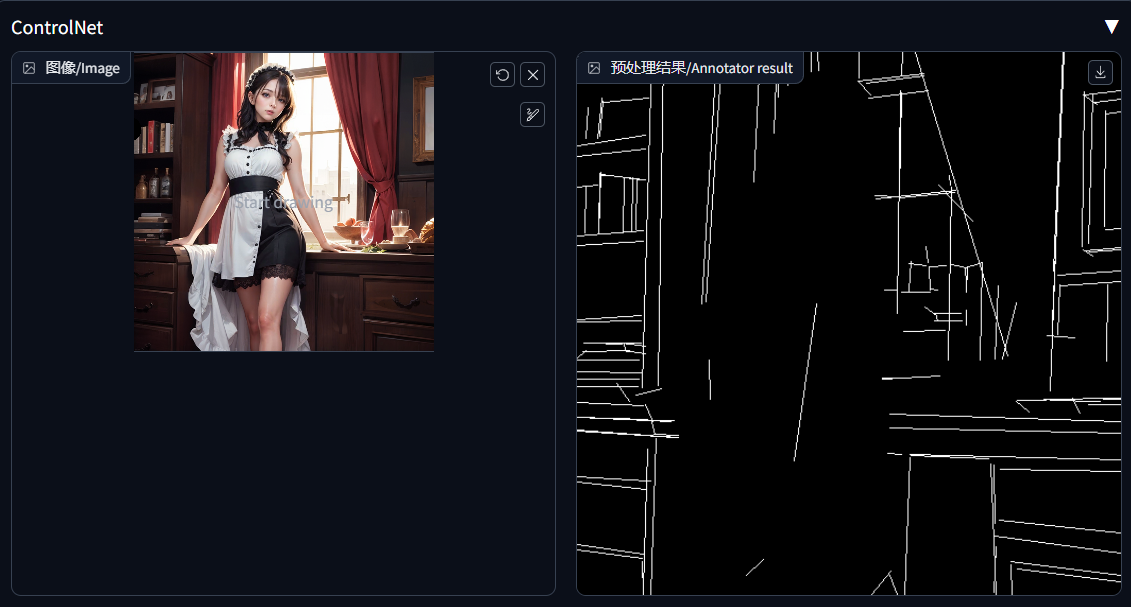
直线检测/mlsd:它是线度检测算法,这种算法不适合人物特征提取,更适合物体和建筑类,室内装潢之类的,有棱有角的图片进行提取。
法线贴图/normal_map:它像3D模型,它可以很好的捕捉空间关系,还可以提供轮廓内部的特征。它比深度算法更多的是一些内部特征,比如裙子的褶皱、胸部的凸起等等。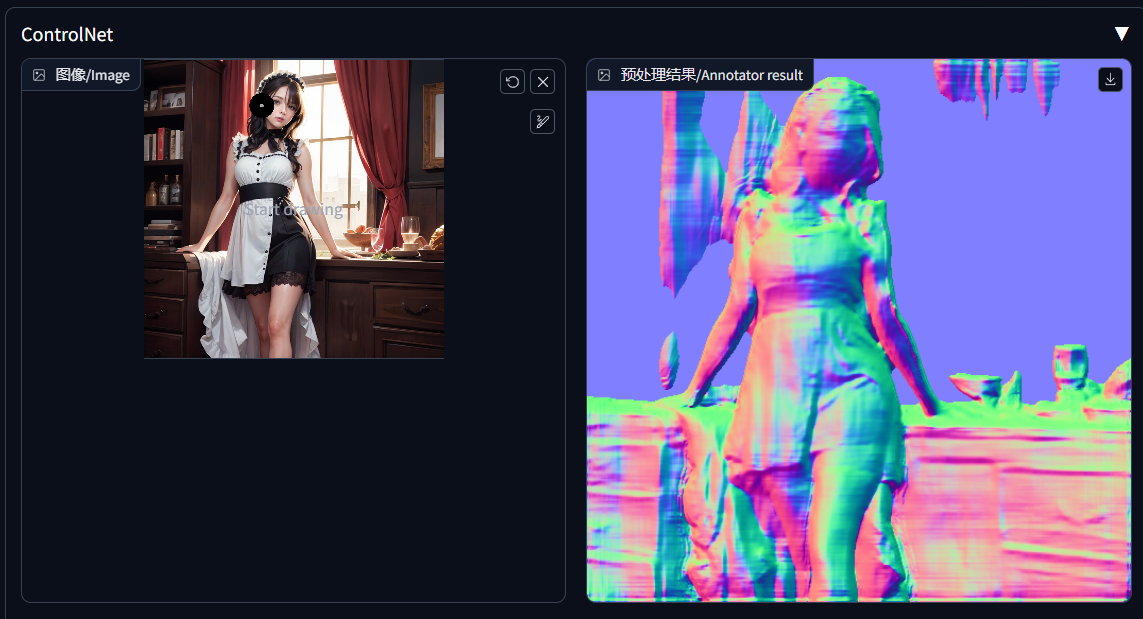
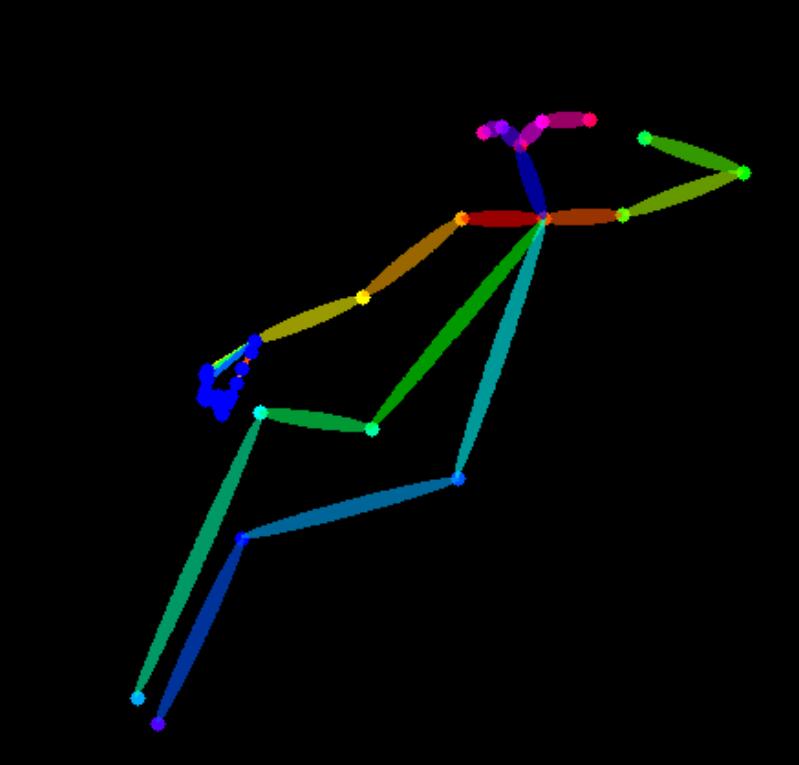
姿势检测/openpose:它更专注于提取人物骨骼姿势特征,会以火柴人的形式帮我们提取姿势,它是一个比较好的人物姿势提取的效果。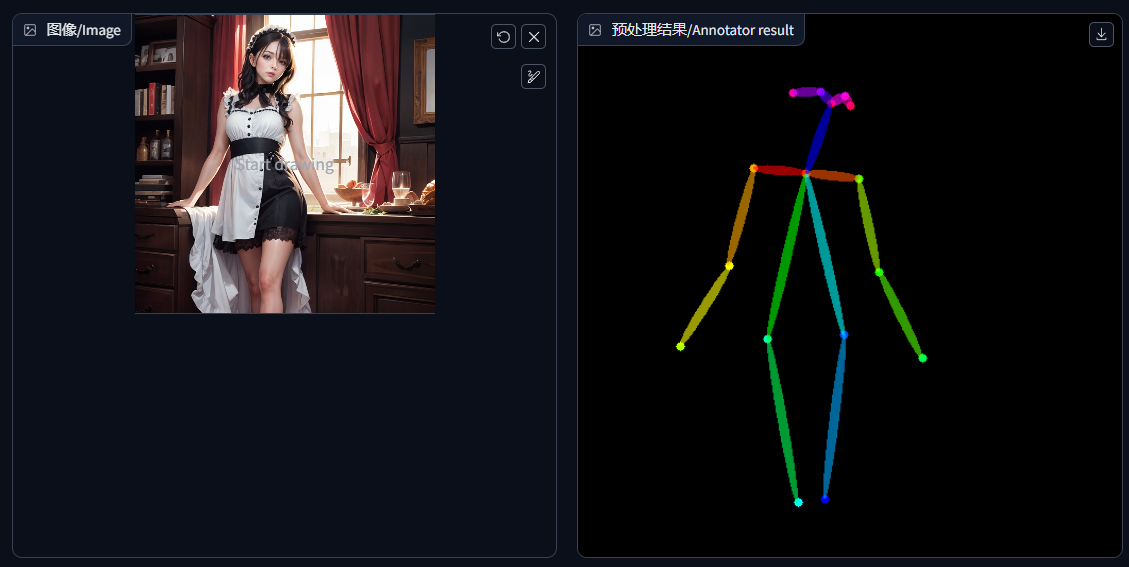
涂鸦/scribble:以涂鸦的形式,这些是很少使用的。
剩下的大家自己点击效果,按照自己的需求对应去使用。
其中比较重要的是,你的预处理器必需和模型对应去使用。

















评论前必须登录!
立即登录 注册