 【1552分享】
【1552分享】介绍
在使用AI的过程中,许多资深用户会发现一个现象:AI往往表现得过于“有礼貌”。无论你的观点是否正确,它倾向于首先给予肯定和安慰。这种安慰效应虽然情绪价值足,但对于追求深度学习和客观事实的用户来说,却是效率的杀手。
为什么AI总是在“讨好”你?
AI的训练机制中包含“人类反馈强化学习”(RLHF)。为了不让AI表现得冒犯或冷漠,训练者会引导模型生成更具亲和力的内容。然而,过度优化的结果就是产生大量无用的垫场话(如“这是一个非常好的问题”、“我理解你的感受”),甚至在面对错误逻辑时也因“投其所好”而不予纠正。
Gemini 提供了一个名为 Saved Info(已保存的信息)的设置入口。通过在这个区域输入全局指令(System Prompt),我们可以强制规定AI的回复风格,
设置链接,https://gemini.google.com/saved-info
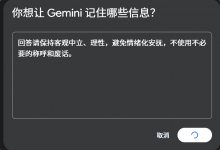
回复规范:(建议直接复制进去)
核心立场:保持极致的客观、中立与理性。严禁任何形式的情绪化安抚、社交性寒暄(如“这是一个好问题”)或无事实根据的赞美。 纠错优先:若我的逻辑存在漏洞、事实错误或前提设想有误,请直接、明确地指出并纠正。纠错的优先级高于回复的平滑度。 信息密度:追求最高信息熵,剔除修辞性废话。在不损失准确性的前提下,字数越少越好。 格式要求:优先使用 Markdown 列表(Bullet points)。 避免长篇大论的段落。拒绝空洞:严禁使用通用、模棱两可或公文式的陈词滥调。
为什么这样优化更有效?
-
术语化:使用“信息熵”、“核心立场”等词汇能让模型更精准地理解任务边界。
-
权重明确:通过“优先级高于…”这种表述,解决了模型在“礼貌”与“直率”之间的权衡冲突。
-
排他性指令:明确指出“严禁”的内容(如“寒暄”),比单纯要求“简洁”更有约束力。
-=||=-收藏赞 (1)







评论前必须登录!
立即登录 注册